Polysemous Visual-Semantic Embedding for Cross-Modal Retrieval
Yale Song (Microsoft Research) and
Mohammad Soleymani (USC ICT)
CVPR 2019
Yale Song (Microsoft Research) and
Mohammad Soleymani (USC ICT)
CVPR 2019
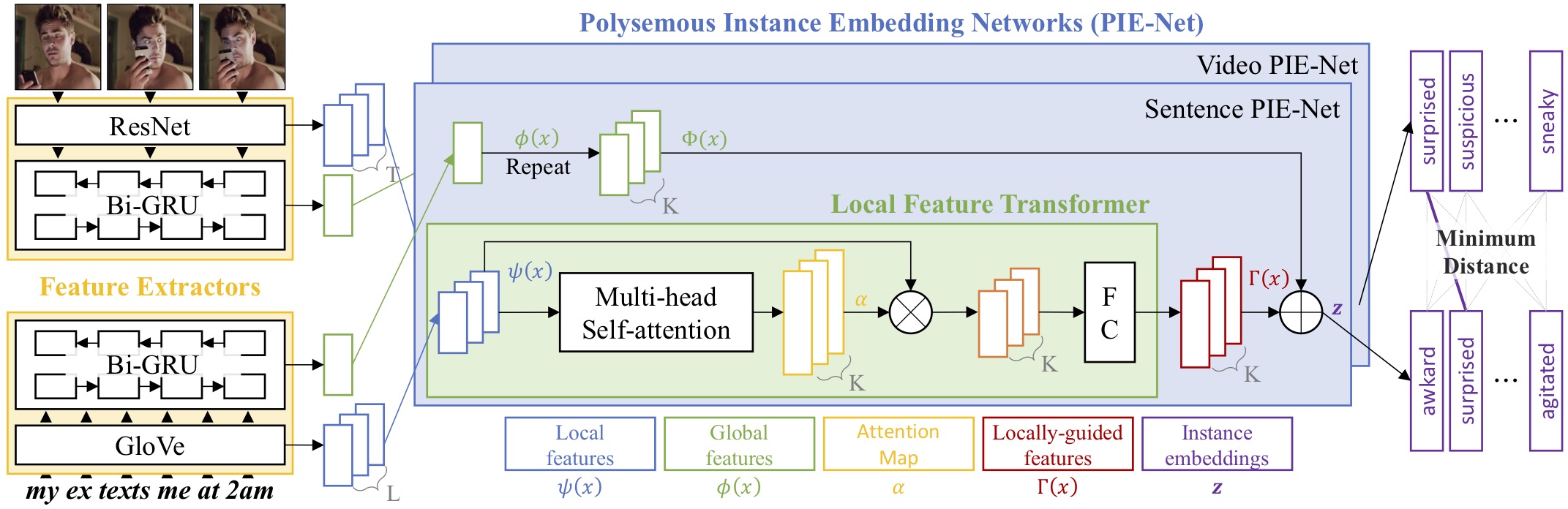
The My Reaction When (MRW) dataset contains 50,107 video-sentence pairs crawled from social media, where videos display physical or emotional reactions to the situations described in sentences. The subreddit /r/reactiongifs contains several examples; below shows some representative examples.
| (a) Physical Reaction | (b) Emotional Reaction | (c) Animal Reaction | (d) Lexical Reaction (caption) |
| MRW a witty comment I wanted to make was already said | MFW I see a cute girl on Facebook change her status to single | MFW I cant remember if I've locked my front door | MRW a family member askes me why his computer isn't working |
 |
 |
 |
 |
We split the data into train (44,107 pairs), validation (1,000 pairs), and test (5,000) sets. The dataset and scripts to prepare the data will become available at our GitHub page soon (pending approval). In the meantime, you may download the dataset at here (metadata only)
Below, for each query image we show three visual attention maps and their top-ranked text retrieval results, along with their ranks and cosine similarity scores (green: correct, red: incorrect). Words in each sentence is color-coded with textual attention intensity, using the color map shown at the top.

For each query video we show three visual attention maps and their top-ranked text retrieval results, along with their ranks and cosine similarity scores (green: correct, red: incorrect). Words in each sentence is color-coded with textual attention intensity.

For each query sentence we show top five retrieved videos and cosine similarity scores. Quiz: We encourage the readers to find the best matching video in each set of results; see our paper (page 11) for the answers.
| (a) MRW I accidentally close the Reddit tab when I am 20 pages deep | |||||
| Rank 1 (0.76) | Rank 2 (0.74) | Rank 3 (0.72) | Rank 4 (0.72) | Rank 5 (0.70) | |
 |
 |
 |
 |
 |
|
| (b) MRW there is food in the house and cannot eat it | |||||
| Rank 1 (0.87) | Rank 2 (0.86) | Rank 3 (0.84) | Rank 4 (0.83) | Rank 5 (0.82) | |
 |
 |
 |
 |
 |
|
| (c) My reaction when I hear a song on the radio that I absolutely hate | |||||
| Rank 1 (0.76) | Rank 2 (0.74) | Rank 3 (0.72) | Rank 4 (0.72) | Rank 5 (0.70) | |
 |
 |
 |
 |
 |
|
| (d) HIFW I am drunk and singing at a Karaoke ba | |||||
| Rank 1 (0.78) | Rank 2 (0.75) | Rank 3 (0.74) | Rank 4 (0.73) | Rank 5 (0.73) | |
 |
 |
 |
 |
 | |
| (e) MFW I post my first original content to imgur and it gets the shit down voted out of it | |||||
| Rank 1 (0.94) | Rank 2 (0.87) | Rank 3 (0.86) | Rank 4 (0.85) | Rank 5 (0.77) | |
 |
 |
 |
 |
 |
|
| (f) MRW the car in front of me will not go when it is their turn | |||||
| Rank 1 (0.84) | Rank 2 (0.83) | Rank 3 (0.80) | Rank 4 (0.77) | Rank 5 (0.75) | |
 |
 |
 |
 |
 |
|
| (g) MRW I get drunk and challenge my SO to a dance off | |||||
| Rank 1 (0.91) | Rank 2 (0.90) | Rank 3 (0.89) | Rank 4 (0.88) | Rank 5 (0.88) | |
 |
 |
 |
 |
 |
|
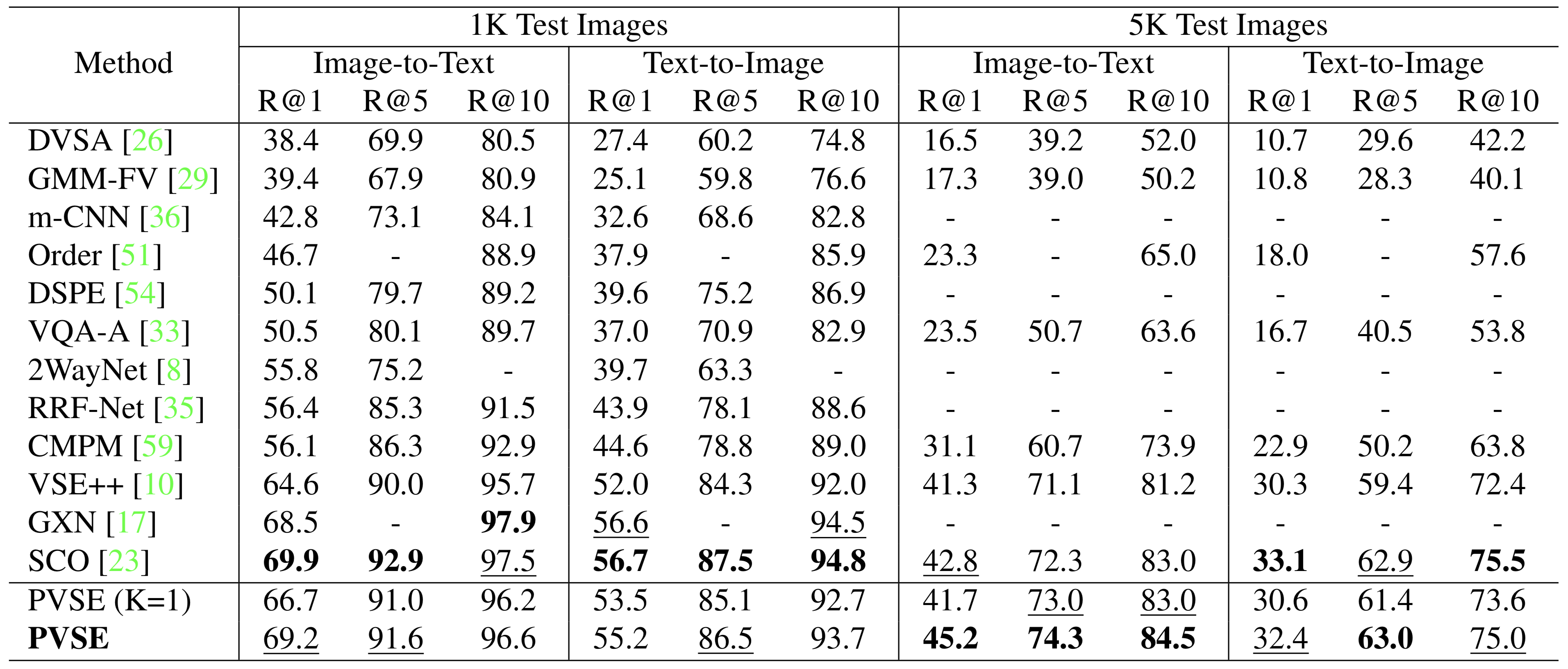
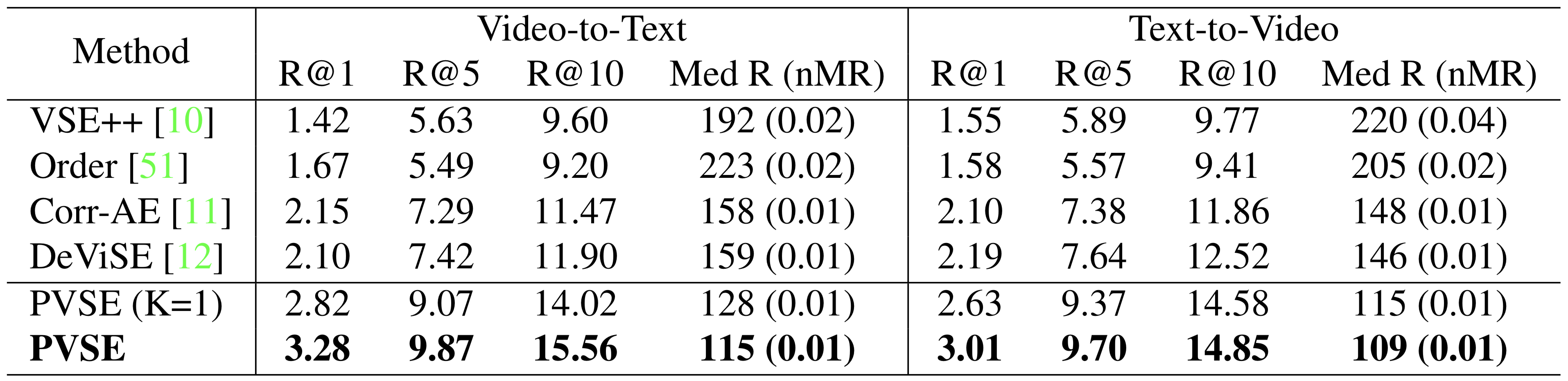
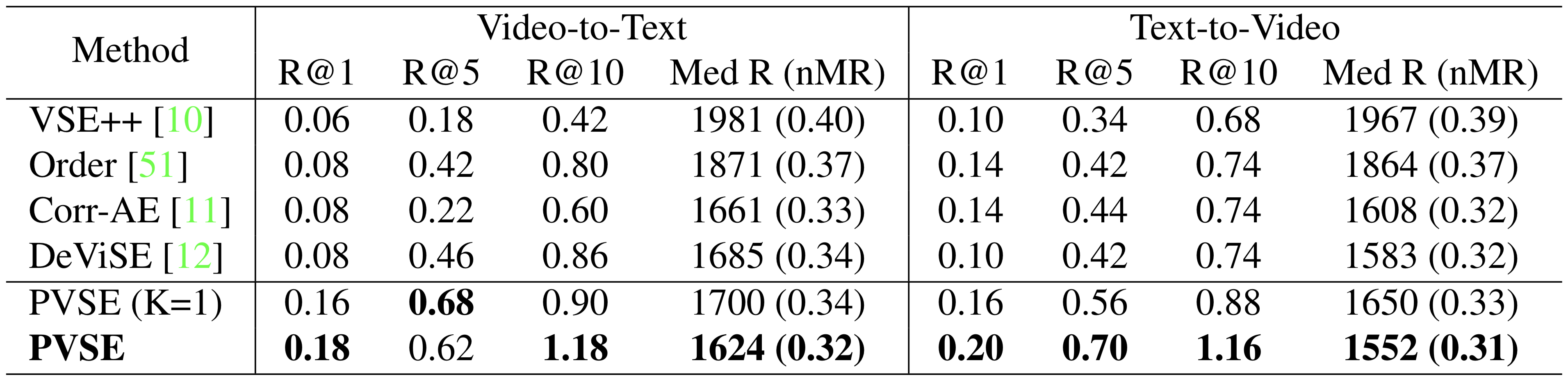
Note: Since our CVPR 2019 camera-ready, we've improved the performance on TGIF and MRW by modifying the data augmentation logic for video data. The new results are reflected in our arxiv version.
